| |
Front Page |
| |

|
Legal Aspects of Compiling Corpora | |||||||||||||||||||||||||||
|
Corpora and corpus analysis tools
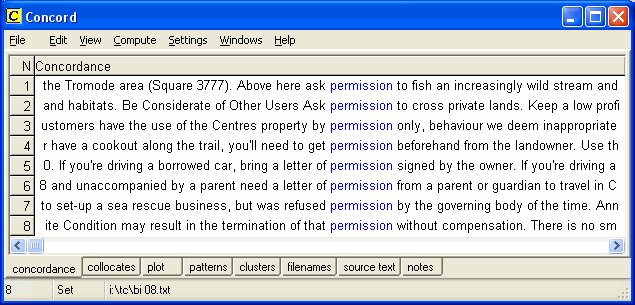
Of course, if you are a freelance translator using a self-compiled corpus as a private reference aid, or if you are a teacher or researcher using a corpus purely for private study and research, there is almost certainly no need to go through the process of requesting permission. But do you need permission if you write an article based on your experiences or on your research with examples of Key-Word-In-Context (KWIC) displays (see Fig. 1) containing short segments of text, as I have done in previous issues of Translation Journal (Wilkinson 2005a & 2005b)? And do you need permission if the corpus is made accessible to a wider user group - for example if it is shared amongst translators in a company, or if it can be freely accessed by others within an educational institution, just as my tourism corpus can be used by all students and staff at Savonlinna School of Translation Studies for teaching and research purposes?
Fig 1: Edited KWIC display for the search word permission generated by WordSmith Tools Citations in Articles In the US, Canada and UK, reference is often made to the concept of "fair dealing" or "fair use", which permits certain acts without requiring the permission of the copyright owner. As Hilton (2001) states: "If the use of a work furthers progress in the sciences and the arts (i.e. if it promotes learning, knowledge, and the public good) and if its use will do relatively little harm to the author's property rights, then it is not necessary to get the author's permission to use the work." The US Copyright Law Section 107 lays down the following four factors to be used to determine whether the use of copyright material in a particular case is a "fair use" or not:
So it would seem that if you display concordance lines from your corpus in order to elucidate certain lexical features, you will not be sued by US copyright owners (and probably not by UK or Canadian copyright holders either) provided you pay attention to the fair use factors, especially the fourth one, which many experts suggest carries the most weight. How does my corpus of tourism texts comply with these conditions? In regard to the first factor, the Tourism Corpus is for non-profit and educational purposes (the situation would be different if copies of the corpus were sold); in regard to the second factor, the brochures used in the corpus are freely-available to the public at no charge (the situation would be more dubious with regard to a school text-book or a best-selling novel); in regard to the third factor, all or most of the text in each brochure is included in the corpus, but in citations, only a few words appear; in regard to the fourth factor, there is absolutely no adverse market effect - on the contrary, it seems that the copyright holders of tourist brochures and tourism websites welcome all the exposure they can get. However, Davies (2002) points out that two lawyers he consulted explained that the copyright law that matters, at least regarding making a corpus available on the Web, is the law of the country from which the corpus is distributed, NOT the country where the original texts were created OR the country from which end users access the materials. So what does Finnish legislation have to say in this matter? According to a lawyer from the Finnish Ministry of Education, downloading material from the Internet and saving it as a corpus requires permission from the copyright holders, as does making the corpus accessible to other user-groups, including students, since there are no fair-use exceptions regarding educational usage in Finnish law as in US law. Similarly, a representative from Finland's Copyright Information and Anti-Piracy Centre agreed that Finnish copyright law does not include any exonerating conditions akin to those in US and UK law, except for the right to copy material for purely personal use (such as private study and research or leisure pursuits). However since Finland joined the European Union in 1995, the development of copyright legislation has been closely linked with Community law. Directive 2001/29/EC of the European Parliament and of the Council of 22 May 2001 on the harmonisation of certain aspects of copyright and related rights in the information society contains the following statement: "This Directive should seek to promote learning and culture by protecting works and other subject-matter while permitting exceptions or limitations in the public interest for the purpose of education and teaching." Moreover, Finland adheres to the Berne Convention on the protection of literary and artistic works, which is perhaps the most important international copyright convention. Article 10 (1) of the Convention states: "It shall be permissible to make quotations from a work which has already been lawfully made available to the public, provided that their making is compatible with fair practice, and their extent does not exceed that justified by the purpose, including quotations from newspaper articles and periodicals in the form of press summaries." So it seems that Finnish law, through its adherence to international law, also recognises the concept of "fair use", though not as explicitly as US law. Unfortunately, Article 10(3) of the Berne Convention states: "Where use is made of works in accordance with the preceding paragraphs of this Article, mention shall be made of the source, and of the name of the author, if it appears thereon." - Mentioning the source of every concordance line in a KWIC display would be a rather cumbersome process! McEnery et al (2006) maintain that the fair-use provisions of copyright law as they apply to citations in published works should operate differently when they apply to corpus-building so as to allow corpus builders to build corpora quickly and legally. McEnery et al suggest that limited reproduction of copyrighted works, for instance in chunks of 3,000 words or one-third of the whole text (whichever is shorter) should be allowed under fair use for non-profit making research and educational purposes.
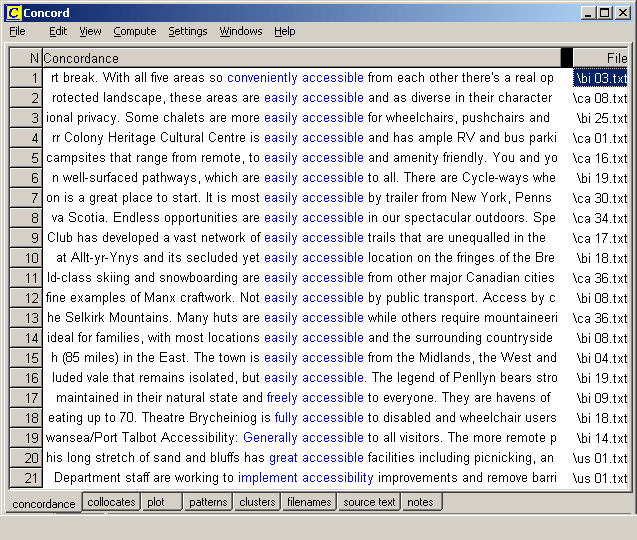
Accessibility to the corpus within educational institutions When considering accessibility to your corpus, the legal situation is perhaps even murkier than that regarding citations from the corpora. Davies (2002), writing about the situation in the USA, states: "A couple of months ago I was talking to a lawyer/professor from another university who specializes in copyright law as it applies to electronic materials and more specifically, electronic materials on the Web. I explained to him a project where I had a large amount of material in a web-based corpus, but users could only see the hits in very short context concordance lines. His view was that because the material that was made available to the end user was so radically different from the original format (i.e. complete texts), there was no problem at all. In addition, I emailed a second professor at another university, who also specializes in copyright law as it applies to the Internet, and she said basically the same thing."
Fig 2: Edited KWIC display for the search pattern accessib* generated by WordSmith Tools However, many corpus analysis tools enable the user to view the concordance line in a wider context, ranging from several paragraphs to, in the case of WordSmith Tools 4 (Scott, 2004), the entire file. Bearing this in mind, one must consider whether the "fair use" philosophy allows in-house accessibility, whereby colleagues use the corpus for research purposes or students use the corpus in the translation lab as a reference tool for improving their translations. Here again, US law suggests that "multiple copies for classroom use" is covered by fair use, and Part III of Canada's Copyright Act suggests that, with certain provisions, there is no infringement of copyright by educational institutions where copies are made of works in printed form. However the ICLT4LT (Information and Communications Technology for Language Teachers) website, referring to advice given by the British Educational Communications and Technology Agency (BECTA) concerning copyright involving electronic materials, suggests that making multiple copies of electronic materials for classroom use has been established as being outside fair dealing definitions. So this would suggest that if the corpus is made available to students on CD-ROMs or on the hard discs of the computers in the translation lab for them to use as reference tools when carrying out translation tasks then fair dealing would cease. And of course if you are intending to sell your corpus, it is extremely advisable to get permission. To quote Kilgarriff (2002): "Copyright law is in general about the case where someone makes money from selling intellectual property: if you are going to sell a corpus, the issues need taking very seriously, as people will be upset by you making money out of selling their text (unless you give them a share)."
Degrees of necessity The following table attempts to summarise some of the points discussed above, though it must stressed that this "guide" is to a large extent speculative and should not be followed blindly, and that the legal situation varies from country to country. But if the circumstances surrounding your corpus project conform mainly to the criteria in the left column of the table you might consider not bothering with the time-consuming effort of requesting permission - and keeping track of permission granted - whereas if it scores hits in the right hand column of the table, you should be on your guard.
Kilgarriff maintains that "to be unequivocally, completely, totally in the clear you need to get copyright clearance from all copyright holders", although he does go on to say that "the law is in its infancy and there is very little which is obviously right or wrong/legal or illegal" and reveals a more cavalier attitude when he continues that if it is only for in-house use, then one simple issue is "who will ever know?".
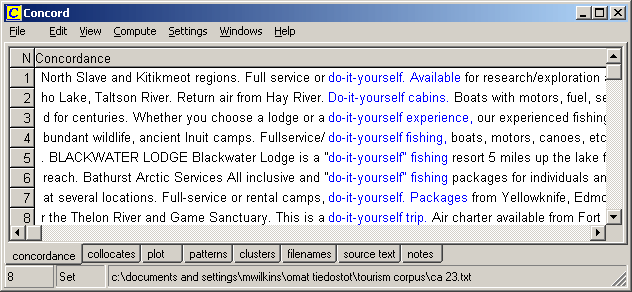
Use it and lose it A number of translator-trainers (e.g. Varantola 2003; Zanettin 2002) have reported on the use of student-compiled "ad hoc"corpora (also referred to as "virtual", "DIY" or "disposable" corpora) in their courses.
Fig 3: KWIC display for the search pattern do-it-* generated by WordSmith Tools But why do such corpora need to be disposable? Couldn't they be open-ended collections - constantly added-to, updated and revised - and perhaps even pooled amongst the students in a group? Or do some translator-trainers think that "ad hoc"corpora are somehow exempt from the copyright laws? If so, I suspect they are mistaken - compiling a corpus on a "use it and lose it" basis is not a way of getting around the copyright laws, though it does reduce the risk of getting caught.
Requesting Permission Requesting permission to use texts in a corpus can be a time-consuming process. Not only do you have to keep careful track of from whom you have requested and been granted permission, but also careful care needs to be given to composing your letters in such a way that the recipients will bother to reply: the letter shouldn't be too long but the recipient should obviously understand the nature of your project. A number of teachers and researchers have expressed their irritation at the time-consuming need to seek permission before using texts in corpora. For example Cooper (2003) expresses his concern at suggestions that it is necessary or even advisable to obtain permissions, and possibly pay compensation, before using texts in such a way, and points out that although this may be a consistent position for corpus developers who are also publishers, it may unnecessarily discourage researchers in other environments.
References Cooper, Doug (2003). In Corpora List Archive "Legal aspects of corpora compiling". Online at http://torvald.aksis.uib.no/corpora/2003-1/0596.html Davies, Mark (2002). In Corpora List Archive "Legal aspects of corpora compiling". Online at http://torvald.aksis.uib.no/corpora/2002-4/0016.html Hilton, James (2001). "Copyright Assumptions and Challenges" EDUCAUSE Review 36/6 November/December, pp 48-55. Online at http://www.educause.edu/ir/library/pdf/erm0163.pdf Kilgarriff, Adam (2002). In Corpora List Archive "Legal aspects of corpora compiling". Online at http://torvald.aksis.uib.no/corpora/2002-3/0253.html McEnery, Tony, Richard Xiao & Yukio Tono (2006). Corpus-Based Language Studies: an advanced resource book. London: Routledge. Scott, Mike (2004). WordSmith Tools version 4, Oxford University Press. Varantola, Krista (2003). "Translators and Disposable Corpora" in Zanettin, F., Bernardini S. and Stewart D.(eds.) Corpora in Translator Education Manchester: St Jerome, pp 55-70. Wilkinson, Michael (2005a). "Using a Specialized Corpus to Improve Translation Quality", in Translation Journal, Volume 9, No 3.
Wilkinson, Michael (2005b). "Discovering Translation Equivalents in a Tourism Corpus by Means of Fuzzy Searching", in Translation Journal, Volume 9, No 4. Wilkinson, Michael (2006). "Compiling Corpora for use as Translation Resources", in Translation Journal, Volume 10, No 1.
Zanettin, Frederico (2002). "DIY Corpora: The WWW and the Translator" In Maia, Belinda / Haller, Jonathan / Urlrych, Margherita (eds.) Training the Language Services Provider for the New Millennium, Porto: Faculdade de Letras, Universidade do Porto, pp 239-248. |
|||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||
 n the last issue of Translation Journal (
n the last issue of Translation Journal (