 | |
|
| |
|
|
 | |
|
| |
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
|
| |
| |
|
| |
|
| |
|
| |
|
| |
|
|

| |

|
Sounding the Language-Elephant’s Trumpet(a guide for intelligent buyers of translation services)by Paul Sutton | |
Part 2
I think this is a very accurate portrayal of the translation industry today. Over the last few decades, demand for translation has boomed, causing chaotic supply-side response. And whereas most markets would stabilize out naturally, chaos in the translation market persists and intensifies owing to deep-rooted ignorance (the fog), exacerbated by great confusion, much of it generated deliberately (the megaphone noise). Down-to-earth readers, with their circuit diagrams and spreadsheets, might object to my use of words like rapture, art and beauty. "We do technology. "We do business," I hear them say. "We're not interested in poetic grace." Just two comments, for the time being:
In any case, the enemy of art, the enemy of engineering elegance and the enemy of personal commitment is ignorance. In the first part of this article, I mentioned two primary sources of ignorance in the translation industry: inertia and chaotic growth. In Part 2 I will be examining inertia, and in Part 3 chaos. Inertia The persistent authority of the written word I mentioned previously that whereas spoken language was the result of slow-moving biological evolution, written language must be considered a product of fast-moving cultural change. But everything is relative, and what might be fast in evolutionary terms still looks excruciatingly slow to the calendar-watcher. Because it afforded permanence and efficient transmissibility for long, complex chains of thought expressed through language, writing must be considered the most important discovery in the whole history of humanity. And for a very long time, the immense power of the written word was wielded by the tiny minority of the population that had access to education. Today, virtually everybody in the Western world can read, and a large proportion of the population can actually produce printed documents that resemble published works. But the written word's long history as a secret code, offering access to knowledge for initiates only, still shows through quite clearly today. For a start, the written word still enjoys an inherent credibility, regardless of whether credence is actually warranted by content. The written word was for so long the exclusive preserve of those in power that it continues to glow with an aura of authority today. I have frequently observed that a reader having difficulty with a text will be more likely to blame his own capacity for understanding than the author's capacity for explanation. Even among peers, the author is perceived as enjoying intellectual dominance, and the burden of achieving understanding will fall on the reader. Two examples:
Users of translated software might even be forgiven for correlating spectacular advances in software useability with declining quality in documentation: after all, modern software-design practice dictates that the user interface itself should provide sufficient implicit guidance to make the explicit help function largely unnecessary. Yet the original English-language documentation is usually perfectly adequate, or even good. And so it should be: it is designed and written with great care by specialized technical authors in well-organized technical documentation departments. Certainly, localization receives no lesser care and attention, judging from the industry-wide standards and procedures developed in recent years in an attempt to guarantee successful localization practice. So how is it that so much care and attention can produce such very bad results? It can only be that the care and attention is misdirected. The power of popular misconception The invention of writing opened the way to efficient communication of ideas across the barriers set by geography, politics and, above all, the passing of time. Thereby, it single-handedly potentiated the emergence of scientific enquiry: transient, short-range, unreliable word-of-mouth speculation on the workings of the universe would give way to a durable system that would enable each successive generation to build solidly on the findings of the last. Sure enough, humankind's boundless analytical curiosity would soon extend to the very vehicle whereby that curiosity was exercised: language. Indeed, enquiry into the nature of language has always held great fascination, perhaps because language makes such a crucial contribution to civilization, perhaps because language is what sets us apart from other animals. And the fascination is enhanced by the powerful political implications of language. Because thought is expressed using language, there has always been a temptation to see crossover between them: for example, oppressors have frequently imagined that rebellion can be quelled by silencing the language in which rebellious thoughts are phrased; and rebels have frequently imagined that rebellion can be consummated by remustering a linguistic identity. History has repeatedly disproved this misconception, yet it persists. Misconception concerning language has the habit of persisting, and this is part of what I mean by inertia. The particular misconception that language in some way determines thought even enjoyed a brief period of academic acceptance as recently as the nineteen-fifties, its best-known proponents being the US linguists Whorf and Sapir. Basically, the Sapir-Whorf hypothesis claimed that a person's ideas would be conditioned by the framework of the particular language available for expressing them. Whorf observed, for example, that the language of the Hopi Indians used dramatically different tense structures from English, and suggested that this might have a bearing on how its speakers actually viewed the passing of time. Few, if any, serious linguists support this hypothesis today. In a way, the Sapir-Whorf hypothesis can be seen as seeking scientific legitimacy for people's tendency to perceive deep psychological differences between themselves and foreigners. Without wishing to accuse Whorf or Sapir of xenophobia, I think we could reasonably say that Whorfianism and xenophobia both derive from a commonplace sense of tribalism, and it is this deep-lying sense of tribalism that maintains the strong current of popular misconception on language. Steven Pinker opens his preface to The Language Instinct with this comment: "Language is beginning to submit to that uniquely satisfying kind of understanding that we call science, but the news has been kept a secret". Very often, the problem is not so much one of secrecy as of unwillingness to accept the encroachment of scientific enquiry into the jealously guarded personal domain of language: in her afterword to The Language Web, Jean Aitchison speaks of the "hornet's nest" of vociferous dissent aroused by her eminently sensible BBC Reith lectures in 1996. I can think of no other area in which flat-earth tribalism continues to enjoy such lasting success. The infinitely expanding layers of the dictionary onion The debate on Whorfianism is central to modern linguistics, and it provides a very useful window through which to examine the inertia that holds back good translation practice. Let us consider the English sentence "I'll pick you up at the station", and its French translation "Je viens te chercher à la gare". A Whorfian analysis of this stock translation might focus on the verb chercher, which in many contexts will mean "to look for". Clearly, the Whorfian might say, a French-speaking person emphasizes the process of seeking out the traveller, whereas his English-speaking counterpart resolves the search to emphasize its result, i.e. the finding and subsequent pick-up of the traveller. Might this not reveal greater uncertainty and pessimism in the French psyche than the English? Hardly! And while we're on rail, what about the Spanish question "¿te acerco a la estación?", which might translate as "can I drop you off at the station?" Clearly, says the Whorfian, a Spaniard will speak of advancing the traveller along his way to the station, but is reluctant to promise that the destination will be reached. Again, nonsense! Both of my rather evident railway-station misinterpretations arise out of false equivalences established by our would-be Whorfian across discrete sentence elements in the two languages. Let's look at the process in detail:
Though the process looks logically valid, both of its component steps are hazardous. The first step (matching "acercar" with "drop off") is only possible because the Spanish and English sentences are short and share a similar structure. Basically, our Whorfian will have detected four basic sentence elements ("I", "you", "drop off" and "station"), then proceeded to match "I" with the "o" verb termination, "you" with "te", and "station" with "estación", thus leaving the Spanish verb "acercar" alongside the English verb "drop off" by elimination. This is hazardous because close structural similarities in proper translation are extremely rare outside the most simple and purely denotational of sentences (of the type "today is Tuesday", to quote the great Argentine writer and translator Julio Cortázar). But what concerns us most is the second step, that of looking up "acercar" in a Spanish-English dictionary. This is even more hazardous, and the hazard is exacerbated by the apparently innocent nature of the look-it-up-in-the-dictionary reflex. For acercar, a pocket Spanish-English dictionary gives the meaning "to bring near", which will be corroborated by our Whorfian analyst's realization that the verb acercar is derived from the adjective cerca, meaning "near". A mid-sized Spanish-English dictionary (Collins) gives "to bring near(er)" or "to bring over", though it also includes the example "acercar algo al oído" as meaning "to put something to one's ear". This inclusion of examples of typical usage is a much appreciated feature of larger dictionaries, and the choice and scope of examples will very much determine the quality of a dictionary. By including examples of typical usage, the dictionary is recognizing that a word in one language can almost never be directly matched to a word in another. This can be seen as practical confirmation of the linguist's theoretical observation that meaning is spread across stretches of discourse that are larger (much, much larger) than the word. The word "acercar" has different meanings in different contexts; alone, it has no meaning, because it is never normally used alone. We can easily imagine a Spanish-English dictionary including my train-station sentence as an example of typical usage. But let's take a large conceptual step ahead, and imagine a really huge dictionary that gives all possible contexts for every word. So would this huge work not be a reliable resource for translators? Would it not legitimize the look-it-up-in-the-dictionary reflex I am so fond of maligning? More significantly, would it not provide a reliable database enabling a computer to perform translation? The answer is no, for three main reasons:
What all this amounts to is that no full bilingual dictionary can ever be written, since this would involve writing infinitely sized and perpetually changing works in as many versions as there were pairs of language speakers. So what? Let's go ahead and do it anyway! Or, at least, let's pretend. According to this model, as the dictionary gets bigger, the translation gets better. In a pocket dictionary, then, the French noun "coup" gets translated as "knock", and that's it. So with just a pocket dictionary, and no knowledge of French, we would be obliged to translate the expression "ça vaut le coup" as "this is worth the knock", which does not really belong to the English language (though it might do if used on television a couple of times). Moving up to a larger dictionary, we'll see "valoir le coup" listed as an entry in its own right. But instead of offering a generic translation for the expression, the dictionary is obliged to resort to typical examples, and among those examples, we do indeed find "ça vaut le coup", alongside the suggested translation "it's worth it". This is about as far as dictionaries ever go, and very reasonably so, since well-chosen examples will be sufficient to give the reader the essence of the meaning, and a feel for how the meaning might change according to context. Let's now broaden the context very slightly, to examine the expression "ça vaut le coup de continuer". Clearly, the dictionary entry for "ça vaut le coup" becomes inadequate, since it would give "it's worth it to continue", which, again, does not belong to the English language. A little twist would give "it's worth continuing", which is only a little better. So our expanding dictionary would have to include a separate entry for "ça vaut le coup de continuer". For example, we might find the translation "we might as well carry on", or "there's no point turning back now", or any of a dozen or more alternatives, depending on the broader context. It takes little mathematics to realize that any dictionary attempting even this degree of contextual comprehensiveness would be so enormous as to be impracticable. In Part 1, I spoke of the UN technical agency that insisted on translating "la tension sur les bornes de la résistance" as "the voltage on the terminals of the resistor". This error was caused by the translator's ignorance of usual electrical engineering parlance, but according to my "comprehensive dictionary" model, we might also say that it was caused by the translator's using a defective dictionary. The dictionary was, apparently, big enough to avoid the even more flagrant error of translating "résistance" as "resistance", but not big enough to include a full enough entry for "bornes". If I could have shown the head of the translation department a dictionary with such an entry, I might have been able to prevent the error. In other words, the error was of exactly the same nature as a schoolchild translating "il a dix ans" as "he has ten years". The dictionary is too small: it lists "avoir" as meaning "to have", but fails to include the special case of expressions of age. A bigger dictionary will fix this particular problem, but it cannot go much further; it could not, for example, reasonably include, as a special case, the expression "on a l'impression de stagner", which might well translate, under certain circumstances, as "this is getting us getting nowhere". In this example, as with a huge proportion of translation, there is little surface similarity between the source and target sentences. Meaning is distributed over large chunks of discourse, and, ultimately, over the discourse as a whole. Deep and surface grammars Virtually everything I've said about dictionaries will also apply to grammarbooks. The dictionary catalogues words, whereas the grammarbook describes how the words are put together to form legitimate sentences. Again, we can imagine grammarbooks ranging from the schoolkid's cribsheet up to an ideal comprehensive grammar, again of infinite size owing to the infinite expandability and variability of language. (Actually, because our ideal dictionary goes beyond words to examine contexts, it will catalogue not only the words in both languages, but also the way the words are put together. In other words, it is a grammarbook as well as a dictionary.) The smaller grammarbooks will stop at the more obvious things like verb conjugations, while the larger ones will go further, to examine issues that the vast majority of even educated speakers are totally unaware of. Take adjective order, for instance. Why do we always say "a lovely big stone house" and never "a stone big lovely house" or any other of the six possible adjective permutations? Apparently, English has such a definite preference for word order here that any deviation is considered ungrammatical. Yet this grammatical rule displays a few very curious characteristics. 1 - It appears to perform no definite syntactical function. Sure, you might say that the "s" suffix on a third-person-singular verbform performs no useful function, since the obligatory subject pronoun provides all the necessary information. But at least you can identify the function the "s" performs. 2 - It lacks the binary right/wrong applicability of most grammatical rules. A "linen green fine jacket" would be struck instantly from any translated clothing catalogue, yet "a grey thundering momentous wave" might just be considered a little poetic. 3 - Everyone could correct "linen green fine jacket", but hardly anyone could formalize the rules they apply to do so. And I do not think there even exists a full account that reliably describes the way we naturally tend to place premodifying adjectives in one order and not another. 4 - The rule appears to operate at such a deep level that nobody ever gets it wrong. Teachers seem to agree that students of English rarely need to be told the order; they seem to know it already. And whereas "hard" grammar features such as verb conjugations can show considerable divergence across geographically close dialects, I can think of no English dialect that varies the order of premodifying adjectives. Glancing through Leech and Svartvik's Communicative Grammar of English, I notice descriptions of even weirder notions such as "end focus" and "end weight", which explain why in English we usually prefer to save the most important or lengthy piece of information for last. These rules are so vague and approximate that it is difficult to apply them consciously, and very dangerous to give them greater dominion than they have. In fact, we should not consider them as rules at all, but as simple descriptions of how the English language tends to behave. This is true of all grammatical rules, though we must recognize that some rules (like verb conjugations) are hard because they govern simple and obvious functions like identifying the person or the time, whereas others are more liquid because they cover more complex functions such as emphasis. At an even finer level of detail, in our ideal comprehensive grammarbook, we would expect to find descriptions of how other complex functions are performed in language. Very significantly, most good dictionaries will include a section giving tips on the use of language functions such as "requests", "comparisons", "opinion" and "permission" (to mention just a few of the headings in the Language Use section of the Collins Robert Senior). Ultimately, just like the "end focus" rule describes one of the mechanisms employed to mark emphasis, so we might expect our ideal grammarbook to describe, for example, ways in which joy coupled with expectation for the future and a shade of reconciled nostalgia is conveyed between social equals of different sex. Very clearly, we have left the realm of objective grammar to enter a very subjective realm that almost resembles literary criticism. At this, ultimate, level of detail, we are very close to examining the way in which thoughts are translated into words. As I mentioned earlier, since there is no limit to the number of potentially experiencable situations to which humans can respond with use of language, with limitless degree of nuance, the full surface grammar (my ideal dictionary plus grammarbook) of any instantiation of language must be considered infinite. In simple terms, this just means that people will always be able to express novel ideas in novel ways; literary criticism is a far-from-expendable resource. But a very big problem arises whenever we touch upon the notion of infinity. An infinitely-sized grammar can fit on no bookshelf, and can fit in no brain. Clearly, then, it must be generated by a mechanism of staggering power and complexity but nevertheless finite size, implemented in the human brain. And this mechanism must be capable of generating full grammars in any instantiation; a child born in Madrid will grow up speaking Spanish whereas a child born in Beijing will speak Chinese. This realization, by Chomsky in the nineteen-fifties, marked a momentous turning point in the history of linguistics. By analogy with Chomsky's term "deep structure", we can thus conceive of a powerful and efficient deep grammar (also referred to as "universal grammar"), common to all languages and used for arranging ideas ready for expression in the surface grammar of a particular language instantiation. Pinker (though he would doubtless object to the term "deep grammar") speaks of "mentalese" when referring to this prerequisite mental representation of ideas. 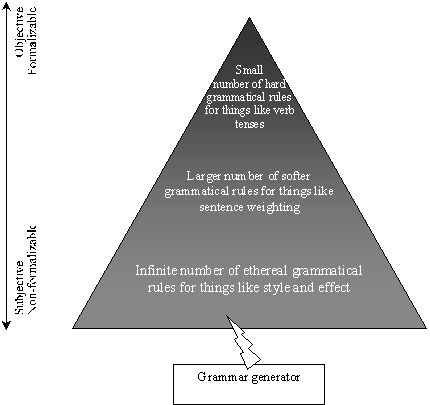 So what does all this have to do with translation? Well, for a start it explains my assertion that there will often be little parallel in surface structures across source and target texts. Bad translation works with small dictionaries and superficial grammarbooks, which ensures close parallelism to the detriment of accurate conveyance of meaning. So does this mean that good translators just work with large dictionaries and grammarbooks? Is this how it works? No! Not at all. Applicability of comparative grammars I have already intimated that dictionaries and grammarbooks become unworkable beyond the rather elementary, but I would like to further emphasize this point with a brief examination of the origins of a bilingual dictionary. What exactly is it that enables us to list the Spanish word "mesa" alongside the English word "table"? It can only be the fact that Spanish people are observed to say "mesa" when referring to the object that British people refer to as "table". In other words, we place members of the two language communities in the same situation and observe their language response. We can do this for all the words in the language, but, as we have seen, there will be many more special cases than main entries, and the number of special cases will increase limitlessly with the length of the extract under examination. Again, very similar considerations apply to grammarbooks. What was it that allowed the first French textbook to equivalate "il a" with "he has" and "il avait" with "he had"? Principally, the fact that the expressions were observed to be frequently and fairly systematically used to express the notion of possession in present and past time respectively. But the parallel only extends to the most elementary of sentences, and then only in a most unreliable manner. A list of even the most basic exceptions to the parallel (e.g. historic present tense and expressions of age and needs) would, again, occupy hundreds of times more space in the grammarbook than the actual verb conjugation. And this is way before we even begin to examine the more esoteric aspects of grammar such as word order, sentence weighting, and the millions upon millions of intricately interweaved factors that determine how a text actually sounds in the reader's inner ear. A small comparative grammar might successfully translate "il a dix grenades" as "he has ten pomegranates". A slightly larger grammar might successfully translate "il a quinze ans" as "he is fifteen". A big grammar might even manage to negotiate the French historic present and translate "il a quinze ans quand il découvre Coltrane" as "he was fifteen when he discovered Coltrane". A grammar larger than any ever written but not entirely inconceivable might conceivably translate "on a l'impression de stagner" as "we're getting nowhere". But what about a text like this: "Car si le premier ministre nous conviait à un échange, c'était avant tout à un échange thermique. On sentait qu'il mobilisait désespérément en lui tout le combustible disponible pour accomplir cette tâche prométhéenne: la fonte de sa banquise individuelle. S'il parvenait, là, tout de suite, à offrir la seule représentation attendue par le peuple, celle de la liquéfaction de l'élite française, de ses certitudes et de son arrogance, alors l'exemple serait certainement contagieux. Alors de proche en proche, les mammouths congelés du syndicalisme, les grévistes raidis sur leurs refus, se laisseraient gagner aussi par la contagion du dégel." A colleague ventured this as a translation into English: "For if the prime minister was inviting us to an exchange, it was above all a thermal exchange. One felt that he was desperately mobilizing within himself all the fuel available for accomplishing this Promethean task: the melting down of his individual ice floe. If he succeeded, there, at once, to offer the only performance expected by the people, that of the liquefaction of the French elite, of their certainties and arrogance, then the example would surely prove contagious. Then step by step the frozen mammoths of trade-unionism, the strikers stiffened in their refusal, would also let themselves be won over by the contagion of the thaw." Very obviously, this translation was performed using a grammarbook. Not in paper form, but in the translator's brain. It was performed algorithmically, applying the low-level algorithms of a small comparative grammar in order to transform the surface structure of the French into a closely parallel surface structure in English. The result does not belong to any viable dialect of the English language, since no English-speaking person (much less a professional journalist like the writer of the French text) would ever reasonably choose to express himself in this way. So what would a more comprehensive comparative grammar have told the translator? Hundreds and thousands of things. I'll list just two:
I could go further. Much further. I could easily fill a dozen pages with a detailed grammatical analysis of this text, and even that would not be complete: another linguist could easily come along and spot things I had missed, and extend my angle of vision on the things I had spotted. I attempted the translation myself and came up with this: "The prime minister had invited us in to the warm, and you could tell he had gathered all the fuel he could find to accomplish the Promethean task of melting down his own personal iceberg. If he managed to meet the public's sole expectation of the moment, by dissolving the arrogance of the French elite, then the process would surely prove contagious and the thaw would soon spread to the frozen mammoths of trade-unionism itself, and the strikers set in their icy stubbornness." To do this, I did not consciously perform any algorithmic conversions. A proper and reasonably thorough algorithmic approach would have been unbelievably time-consuming, because it would have involved developing that twelve-page grammatical analysis full of literary-criticism-type commentary along the lines of the two points I made above. As well as taking far too much time, this would also have been unreliable because the base of our triangle is so immense that I could never be sure of covering it all. So what did I do? I crossed the river between the two languages at the only place where it is actually bridgeable, at the source, i.e. at the grammar generator. Specifically, I read the text, made sure I understood all the ideas and the whole of the argumentary plot perfectly, put myself in the author's place, and wrote exactly the same ideas in English, following exactly the same argumentary plot. Because the author was a professional writer himself, I had to assume that the argumentary plot, including a grossly overworked metaphor that didn't please me personally, was wholly intentional and carefully planned. As you might expect, my colleague claimed that I had "rewritten" the text instead of translating it, but in fact, my translation stands at the absolute upper limit of acceptable literality. (A case could be made for a more liberal approach, especially if the text was intended for readers with no prior understanding of the French political situation at the time.) Anything more literal than this should not properly be considered a translation. In a technical or business translation I would almost certainly have had to correct the argumentary plot to ensure that the resulting text was coherent and therefore viable in English. Note that a full understanding of the text requires an understanding of the author's personality and frame of mind. This means a translator must be a bit of an actor, a bit of a mind-reader. It means the translator must be very sensitive indeed to the way people use language to express their ideas. And it means the translator must be able to write at least as well as his authors. As we saw in Part 1, if you can't write, you can't translate. Crucially, whereas the algorithmic approach addresses words, the read Õ understand Õ write approach addresses ideas. Translators do not translate words: they translate ideas! 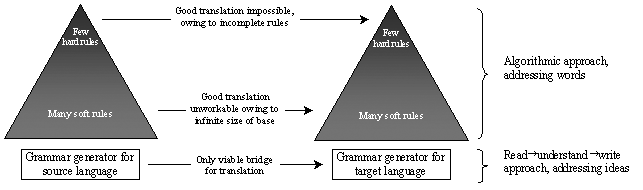 Statistical proof Because the algorithmic, overliteral approach is such a persistent impediment to good translation practice, let me just offer one more conclusive proof that, despite powerful support from big-name writers like Nabokov and Kundera, it lacks any justification whatever. Every language divides reality up into segments amenable to convenient description through the use of words. Some segments have such obvious dividing lines that they are common to all languages. This applies, for example, to days of the week, everyday objects and everyday actions. Since people of all cultures have arms and legs, all languages (to my knowledge) have discrete words for these items. But as soon as we move away from the perfectly clear-cut (Cortázar's "Tuesday"), we find that different languages use different segments. To take some extremely elementary examples, French has several words for the English "valve" but ostensibly only one word to cover the English "like" and "love". Spanish has two verbs for the English "to be", and, no, this does not imply any kind of existential dilemma. It's just that in mapping reality, each language is forced to adopt some rather arbitrary decisions in the segmentation it uses; imagine taking a large picture then giving it to fifty different people to saw up into jigsaw pieces. You wouldn't expect any two pieces from any two jigsaws to be identical. One result of the difference in segmentation is that certain words and expressions can, to the algorithmically-bound translator, appear extremely difficult to translate. Classic examples from French include "animation" and its derivatives (used very liberally to describe situations as diverse as extracurricular activities, pop-up books, piped music, riotous nightlife, busy marketplaces, sales drives and workgroup management) and "enjeux" (variously translated as "implications", "stakes" or "challenge"). Young translators will frequently ask "how do you translate animation here?", to which the only possible answer is that you don't translate the word "animation" at all. What you translate is a much larger chunk of text, expressing an idea for which French just happens to use a different language segmentation. To make my statistical proof, let us just consider a single simple example from English: the verb "afford". French has no single word for the English "afford", so where an English speaker might say "we can't afford it", his French-speaking counterpart in the same situation might typically say something like "on n'a pas les moyens". We might therefore consider these sentences to be translation equivalents, in certain contexts. But let us now consider the inherent dissymmetry between French-to-English and English-to-French translation across these translation equivalents. When translating from English to French, the translator is immediately confronted with a problem for which there is no ready slot-in solution, and he is therefore obliged to find a workaround, along the lines I suggest. The problem arises in the other direction, from French to English, since here there are a couple of readily available slot-in solutions, such as (very literally) "we don't have the means", or "we haven't got the cash". An algorithmic approach will therefore systematically fail to find the solution that uses the verb "afford". Now I'm not saying the slot-in solutions will always be wrong, or that the solution with "afford" will always be right. Far from it! All I am saying is that the "afford" solution will sometimes be right (simply because English speakers in this situation will be likely to use this expression), yet it will never be found by algorithmic means. It follows that a large corpus of algorithmic translation (large enough for statistical analysis to be significant) will be systematically deficient in certain expressions that would be found frequently in a similarly sized corpus of native writing. In other words, algorithmic translation cannot be faithful since it fails to reproduce anything like the statistical breakdown of words and expressions that we would find in native writing. It might be argued that even an algorithmic translator could slot in "we can't afford it" whenever he sees "on n'a pas les moyens". I would argue back by simply taking a slightly more complicated usage of the verb "afford". In a situation in which an English speaker might say "we can't afford not to", his French counterpart might typically say something like "il faut absolument", or "c'est essentiel", and though these expressions might at first sight seem blander than the English, since they lack the sense of implied threat, we must bear in mind that this aspect of meaning can perfectly well be conveyed elsewhere in the French text; as we have already seen, meaning is distributed broadly across large chunks of text. In this instance, then, I think it is clear that few algorithmic translations would manage to reproduce what is a very commonplace English expression. Again, if an expression occurs very frequently in a large corpus of native material but hardly ever in a large corpus of translated material, we can only conclude that the translation method is defective. Click here to continue. |
|
|
|
 n a huge field there are hundreds of horses with their riders, of all styles and abilities: the clumsy, the dainty, the anxious, the confident, the timorous, the intrepid. As the curious visitor approaches he is fearful of the noise, more like a battlefield than a horse show. But little by little, straining his ears, he begins to make out some of the cries. "Fly with Pigasous." "Look at me: this is the way to ride." "Leave nothing to chance: sign up for quality-assured riding classes now." Some riders are using megaphones to make themselves heard, but this leaves them off-balance, and their horses, frightened by the distorted electronic cackling, start bucking and rearing uncontrolledly. Riders often fall off, though few but the seriously injured will let that interrupt the flow of speech: "Spirited, eh? Just how they should be! Ride with me and you'll be a Cossack in a matter of months".
n a huge field there are hundreds of horses with their riders, of all styles and abilities: the clumsy, the dainty, the anxious, the confident, the timorous, the intrepid. As the curious visitor approaches he is fearful of the noise, more like a battlefield than a horse show. But little by little, straining his ears, he begins to make out some of the cries. "Fly with Pigasous." "Look at me: this is the way to ride." "Leave nothing to chance: sign up for quality-assured riding classes now." Some riders are using megaphones to make themselves heard, but this leaves them off-balance, and their horses, frightened by the distorted electronic cackling, start bucking and rearing uncontrolledly. Riders often fall off, though few but the seriously injured will let that interrupt the flow of speech: "Spirited, eh? Just how they should be! Ride with me and you'll be a Cossack in a matter of months".